
Table of Contents
OVERVIEW
This chapter reviews several major learning theories related to using graphics in instruction. While not pretending to be a substitute for a more thorough description of these psychological foundations, this chapter should provide a substantive review of major points and issues that should be considered and understood when designing graphical displays for instruction. Behavioral and cognitive learning theories are reviewed and compared, as are theories related to visual perception. Some of the topics include perception, attention, memory, and motivation. Particular attention is given to the theory underlying computer animated displays.
OBJECTIVES
Comprehension
After reading this chapter, you should be able to:
Application
After reading this chapter, you should be able to:
The purpose of this chapter is to provide an overview of some of the psychological foundations related to learning from graphic displays. This chapter is solely theoretical in nature. It is easy to get the feeling sometimes that theory just gets in the way of instructional design. However, if the goal of instructional design is to affect learning, it seems reasonable that knowledge about learning and cognition should help in making appropriate instructional design decisions. This chapter will present some general themes related to psychological processes and try to relate these to the design of instructional graphic displays. A firm theoretical grounding in the psychological foundations should help to explain and predict some of the conditions under which graphics (static and animated) support learning, as well as those conditions under which graphics do not support or are detrimental to learning. These principles extend to all instructional environments involving graphics, including multimedia.
LEARNING THEORY: A PRIMER
Learning theory has had considerable influence on instructional practice in general, and computer-based instruction in particular. Main ideas of the two dominant classes of learning theories -- behavioral and cognitive -- will be briefly presented. Each makes qualitatively different assumptions about how people learn and remember.
Behavioral Learning Theory
The design of computer-based instruction has gone through an evolutionary cycle. One of the strongest influences on instructional practice in America in this century has been behavioral learning theory and its applications, such as programmed instruction. Although a definite conceptual shift toward cognitive views of learning has occurred in instructional technology, behavioral designs are likely to continue to dominate instructional practice.
Behaviorism is founded on the formation and strength of stimulus-response (S-R) associations (Gropper, 1983). An instructional stimulus is presented, such as a screen containing computer text or graphics, that prompts the learner to respond in an overt, observable manner, such as by typing an answer. The relationship between the stimulus and the response is strengthened through the use of reinforcement.
Operationally, the stimulus can be defined as either the material to be learned or the instructional event that leads to the learner's initial response. One of the basic goals of behavioral methods is to attain a measure of control or predictability of given instructional stimuli. The repeated use of particular stimuli helps to establish predictable control of learner responses, placing student responses under a form of stimulus control. Initially, for example, learners have no innate reason to press the <SPACEBAR> on a computer keyboard or to aim and click on a screen icon, but such responses can be readily elicited, thereby placing the desired response under stimulus control. Through systematic stimulus control, responses can be shaped through the presentation of directions or the repeated presentation of the same stimulus requiring the same response, paired with appropriate reinforcement for the desired response.
The response is the learner's overt behavior made in response to the instructional stimuli. The learner's response is the only recognized behavioral link to the instructional stimulus. Therefore, it is crucial that a causal link between stimulus and response be established in order to evaluate the effectiveness of the instructional stimulus. It is important that the learner clearly understand what response is required in order for the S-R bond to be formed. The response must be judged as appropriate or inappropriate in clear, objective terms, and this information is then conveyed to the learner as feedback. Instructionally, responses are elicited through the presentation of instructional activities and shaped through the presentation of systematically controlled activities, responses, and response consequences.
After a response is made and judged, a follow-up stimulus is presented to the student as a consequence to the response. This learner-activated stimulus, or reinforcement, is applied systematically to strengthen desired responses and is chosen conditionally on the desirability of the response. A key element of reinforcement is the principle of contiguity, where reinforcement is given closely in time with the response to be strengthened (Gagné & Glaser, 1987). Reinforcement for learner responses can be positive or negative. Both positive and negative reinforcements are designed to increase desired responses (Kazdin, 1980). Correct answers typically receive positive reinforcement in the form of statements such as "Good job!" or "Super!"; incorrect answers receive negative reinforcement such as "You missed that one" or "Your answer is incorrect." Presumably, learners seek to avoid negative reinforcement by striving for appropriate or correct responses during response opportunities that follow. In the absence of the overt reinforcement available during instruction, behaviors are thought to be maintained by the intrinsic rewards of success.
Whether or not reinforcement actually is "reinforcing" to a student is determined by trial and error. Obviously, things that are strongly reinforcing to one person may be totally ineffective for another. A child who is a fan of superheroes, such as Superman or Batman, should find such graphics as reinforcing for correct responses and would be expected to seek to make more correct responses on the condition that similar graphics will follow.
Instructional designers often fall prey to forgetting that care should be taken to reinforce only correct responses. Fanciful graphics, used to add cosmetic or affective appeal to the learner, can be harmful when used as feedback to incorrect responses. The worst-case scenario is when the consequence of a wrong response is actually more reinforcing than that provided for a correct one. A good example is from an actual CAI lesson on weights and measures, where a student is asked to convert gallons to quarts. If the student responds correctly, for example, that four quarts equal one gallon, appropriate (though boring) praise is given, such as "That's correct." However, if the student answers three quarts, the well-intentioned lesson shows, via animation, a gallon jug pouring its contents into the three awaiting quart containers with the last quart being spilled onto the floor. If the student finds a graphic of spilled milk more reinforcing than the praise, you can wager that more incorrect responses will follow.
Reinforcement and feedback are commonly misinterpreted as being synonymous. Though they may be used similarly in practice, there are several important distinctions between them. Feedback generally includes information related to the accuracy of a response, with the purpose to guide the student to make correct answers (Kulhavy, 1977; Schimmel, 1988). Feedback can be instructive without necessarily increasing desired responses. Reinforcement, on the other hand, can increase the probability of desired responses without necessary ties to the substantive requirements of a response. For example, information that smoking causes cancer may not actually lead a spouse to stop; however, always leaving the room when he or she lights up, even without explanation, may lead to decreased smoking. It is possible, therefore, to provide informational feedback that does not necessarily increase the probability of desired responses; likewise, it is possible to provide reinforcement that offers little informational feedback. Feedback that is reinforcing yet informational satisfies both behavioral and cognitive descriptions.
Though both feedback and reinforcement are continuously applied during typical CBI lessons, this practice may be both unnecessary and inappropriate. Reinforcement instead can be provided intermittently where only selected occurrences of a response are reinforced. The purposeful application of reinforcement schedules is important, since one goal of instruction is to decrease the amount of sustained reinforcement needed to elicit and maintain desired responses (Reynolds, 1968). Intermittent reinforcing is believed to be much more powerful than continuous reinforcement. A good example is a gambler at a slot machine. Winning only occasionally provides strong incentive to linger a little longer.
In order for instruction to be effective in most settings, the learner must respond to stimuli that are not necessarily identical to one another. In most cases, it is impossible to anticipate and teach all variations under which instructional stimuli might be encountered. It is essential that learners first be able to discriminate among classes of stimuli and then generalize relevant stimulus features and attributes to include appropriate alternatives. For example, though the short vowel word "cat" may be presented via individual worksheets, the student is expected to read "cat" from books, pet food boxes, and computer displays. Ambiguous cues can force the student to incorrectly discriminate or generalize. An illiterate shopper may choose a lemonade brand based on the picture of a lemon on the label, only to find out later at home that dish soap was purchased by accident.
During instruction, numerous stimuli are presented. Part of the learner's task, therefore, is to selectively identify relevant stimuli from irrelevant stimuli. Graphics are just one source of visual stimuli competing for the student's attention. What determines which stimuli will be attended to and which will be ignored? The answer involves the issue of selective attention, a phenomenon that has been studied under both behavioral and cognitive frameworks. From the behavioral point of view, when two or more stimuli are provided, the learner will select the one that most easily results in the correct response. This is known as the "principle of least effort" (Underwood, 1963). A typical behavioral task would be to provide a student with a card displaying both the word and picture of an object, such as a cat. If the student's task is to identify the object, the principle of least effort predicts that the learner's attention will focus predominantly on the picture instead of the word in order to achieve a correct response (Samuels, 1967). In learning how to read, of course, the goal would be to shift stimulus control from the picture to the word.
Several behavioral techniques can strengthen desired S-R associations, such as showing the printed word and saying the word. Cueing helps learners to interpret complex stimuli by providing contextual "hints." Shoppers who buy dish soap instead of lemonade would benefit from paying attention to which supermarket aisle they are in, for example. Prompting refers to supporting instructional features that amplify critical stimuli features, such as important words or concepts (Hannafin & Peck, 1988). In effect, prompts emphasize relevant stimuli by explicitly directing learners to relevant aspects of the lesson. In practice, however, stimulus-response associations should not be dependent upon prompts that will be unavailable under actual performance conditions. Therefore, prompts should be progressively faded from instruction to ensure that responses can be elicited by appropriate stimuli alone. Responses are then shaped, both individually and in complex chains, to meet predetermined response requirements.
The principle of least effort requires instructional designers to be wary of providing any stimuli, such as pictures, that may compete for the learner's attention. If the picture is perceived as providing the information necessary to respond correctly, it will dominate which S-R associations are formed and which are neglected. If a student learns beginning reading skills with the use of pictures, for example, the strength of the S-R association of the picture and the task may be stronger than other S-R bonds. Therefore, if a picture is present, a learner may defer to the picture by default. From a behavioral point of view, therefore, graphics can be potent stimuli resulting in both appropriate and inappropriate learning. Graphics can provide the foundation for strong S-R associations or they can be disruptive or cause interference (Willows, 1978). Research has shown that learners vary in their susceptibility to interference by graphics. For example, learners with poor reading skills seem particularly vulnerable (Samuels, 1967).
Although S-R associations are the basic unit of analysis in the behavioral model, few tasks involve isolated stimuli or address only simple responses for simple associations. In practice, individual associations are linked together to produce networks of interdependent S-R chains. Successful learning almost always requires complex sets of related S-R events to collectively guide responses. The learning of complex tasks and problem solving is explained through chaining, a point frequently challenged by cognitivists.
Strict behavioral applications to learning frequently come under criticism. For example, behavioral designs, though usually considered quite effective for lower-level learning such as that associated with verbal information (see chapter 2), tend to be insufficient for higher-level learning such as intellectual skills (which include problem-solving).
Cognitive Learning Theory
In contrast to focusing on strengthening S-R bonds, cognitive orientations to learning consider the actual thought processes occurring in between the stimulus and the response as the most important aspects to learning. The emphasis is on how a learner selects, perceives, processes, encodes, and retrieves information from memory (Di Vesta, 1987).
The Information-Processing System
There are many aspects to cognitive psychology. However, almost all recognize some model of human cognition based on information processing. Information processing models are just that -- models. They are not meant to describe learning in any physiological way. Instead, these models provide a computer analogy to help understand the learning process by suggesting that the processing of information by humans is like that of a computer. Information processing provides a vocabulary for describing mental events, as well as explaining why learning does or does not occur. A standard criticism of information-processing theories is that they generally focus on semantic learning and do not take into account social and emotional aspects of learning. However, this criticism is more related to the application of the models, rather than the models themselves. There is no reason why an information-processing model cannot be extended to serve these functions as well. It is also important to recognize that the S-R model of behaviorism is subsumed in information processing. Of interest, however, is what happens in between the stimulus and the response; in other words, what goes on between one's ears.
Information-processing models describe learning as a series of knowledge transformations, starting with the input of information (stimulus) from the environment, and ending with either an output (response) or the storage of the information in memory, or both (Dodd & White, 1980; R. Gagné, 1985; E. Gagné, 1985). These transformations require a progression of nonobservable, mental steps for learning to occur.
Figure 4.1 shows a standard form of the information-processing model. First, the learner must filter the large amounts of stimulation coming from the environment. This information is transformed by the senses into neural information, where it exists briefly in the sensory register (Sperling, 1960). However, the amount of information available to a learner at any one moment in time can be enormous. The human response to this bombardment of information is known as selective perception, which is the process where only a small portion of the incoming stimuli will be given any consideration at all. Successfully ignoring all stimuli except the most pertinent and relevant is an extremely important ability, without which life would be unbearable. Because of selective perception, the bulky sensation of a winter coat soon fades away. Even the most subtle stimuli, such as the stray floating particles in the vitreous humor of the eye, called nuscae volatantes (Latin for "flying gnats") or more commonly "floaters," would soon overwhelm your attentional processes if your perceptual system did not filter them out.
The main instructional issue related to selective perception is attention. Current theories of attention have evolved from earlier ones based on mental "filters" (Broadbent, 1971) and the limited capacity of many mental operations (Norman & Bobrow, 1975). Attention involves cognitive decisions related to which information will be attended to, given the fact that the environment contains far more information that any one person can handle at any given time. Information-processing theories describe attention as consisting of a general sequence of stages, some of which are made subconsciously, such as sensory input, and others consciously, such as selective attention as introduced in the last section. Selective attention, therefore, implies the element of intentionality in focusing on one set of information while blocking other incoming information. In this way, selective attention serves a gate-keeping function. These perceptual and attentional processes are believed to be influenced by both the intensity of the input and expectations based on prior knowledge -- these are known as bottom-up and top-down processing, respectively (Anderson, 1980). Research has shown that people are often predisposed to select information based on physical characteristics (e.g., color and motion), as well as information that is novel or unique (see Dodd & White, 1980, for a review). Visual or aural intensity, externally provided cues, prompting, and organization of the material are among the many presentation factors that can facilitate attention.
Research has shown that attention is naturally drawn to the novel or unique (Fleming, 1987). Obviously, the use of graphics can be an important strategy for influencing attention, but only if the graphics are used deliberately in novel or unique ways. Graphics in a lesson saturated with illustrations would, of course, soon lose their attention-gaining capability, as novelty effects eventually wear off. Attention-gaining graphics should be used judiciously in order to optimize their effectiveness.
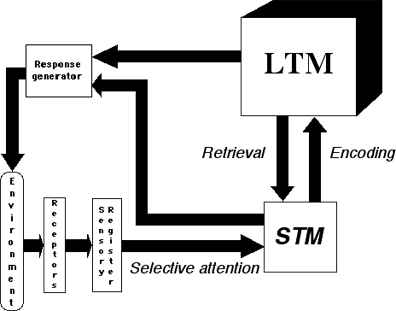
Figure 4.1
The information-processing system.
Selected information is stored temporarily in short-term memory (STM), or working memory. STM acts essentially as a buffer containing information units to be acted upon. It does not, by itself, serve as a permanent storage location, but instead acts as a "broker" for the selective exchange of information from instruction, prior knowledge, and long-term memory. STM is analogous to a computer's random access memory (RAM). Unlike computers, however, STM has a severely limited capacity. Although the limits are debatable, STM is generally considered to hold five to nine informational units. Each unit corresponds roughly to one idea or expression (Miller, 1956). Some researchers have proposed strategies, such as mnemonics or meaningful "chunking" of information, to increase the functional capacity of STM (Chase & Ericsson, 1981). For example, memory for the phone number 355-1224 would be facilitated by noticing the mathematical coincidence that 24 is two times 12 in the final four digits. This would reduce the burden on STM from the seven original informational units (roughly one unit per digit) down to about five.
Again, graphics offer the potential for an efficient means for coping with the precious and limited processing capabilities of STM. Similar to the principle of least effort, students are likely to revert to a given graphic because they are apt to perceive the amount of invested mental effort (Salomon, 1983) as being less for the graphic than for the surrounding text, even though this may not be the case. If this would happen, the graphic would be serving to subvert the usefulness of the text by serving as a distraction. On the other hand, graphic organizers can much more efficiently represent information when compared to presenting pure verbal information, such as the spoken or written word.
If information is to be learned, it must be transferred from STM to long-term memory (LTM) -- a permanent mental storage location analogous to computer disks or magnetic tape. In order for this transfer to be successful, the information must be coded. The retrievability of knowledge afterward is directly related to the manner in which information is coded. From an instructional perspective, however, it is important that successful strategies are applied to strengthen the coding of relevant content, since poorly coded information can be discarded at any point prior to successful storage in LTM (E. Gagné, 1985).
Encoding and Retrieving Information to and from Long-Term Memory
Although controversial, many cognitive psychologists believe that once information is successfully stored, or encoded, in LTM, it is never lost. Subsequent problems in remembering or recalling encoded information is believed to be a matter of deficient retrieval strategies, rather than simply of forgetting (i.e., storage deterioration). Successful retrieval of information from LTM, therefore, is dependent on both the quality of initial encoding into LTM and the methods governing retrieval -- both those supplied by the lesson and those triggered solely by individual learners.
Beyond the processing system, and central to the likelihood of retrieval, is the manner in which information is stored within LTM. Knowledge is believed to be stored in LTM in a variety of mental representations, including propositions, productions, and images. A proposition is the smallest, single information unit, corresponding generally to an idea. Declarative knowledge consists of propositions. It is useful to consider propositions as simple idea units, rather than as actual words or sentences (Wanner, 1968). Productions, on the other hand, represent procedural knowledge. Declarative knowledge can be thought of as knowing about something, whereas procedural knowledge is knowing how to do something. Productions are conditionally based action sequences that are executed under highly specific conditions, similar to an if-then condition programmed into a computer. They are linked together in production systems where one production leads directly into the next production. A simple example of a node-link representation involving propositions and productions is shown in Figure 4.2. Functionally, productions and production systems provide a parallel to the S-R associations and S-R chains aspects of behaviorism, though their conceptual roots and underlying assumptions are quite dissimilar.
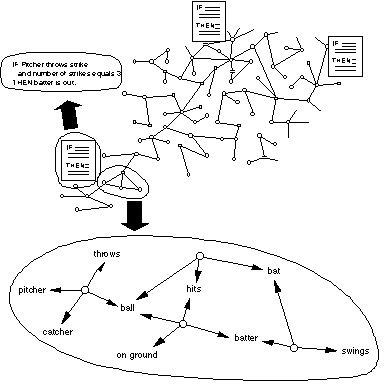
Figure 4.2
An example of a propositional network.
Schema is another psychological construct, meant to be more metaphorical than physiological, that represents an individual's entire organized knowledge network (Norman, 1982), as well as the representation of that knowledge (Rumelhart & Ortony, 1977). Schema theory has been used to describe interrelationships among prior knowledge structures. Just as a play requires characters with defined roles and associations, schemata has certain variables and slots that must be filled for meaning to exist (Rumelhart & Ortony, 1977). Each individual develops and refines a multitude of individual schemata; each schemata is instantiated (triggered, then enacted), in order to understand or make sense of complex situations. Furthermore, schemata systematically access one another. Examples of common schema are the "scripts" associated with going out to eat at a restaurant, riding a city bus, and going out on a date.
Schema theory refers to two main types of mental processing: top-down and bottom-up. Bottom-up mental processing begins with isolated facts that eventually instantiate a schemata. Top-down processing begins with a schemata leading a person to search for appropriate information to satisfy or complete the schemata. An everyday example of top-down processing is seeing a person walking away from you down and across the street in a way that looks familiar. If the walk triggers the schemata of "my good friend Joe," you might yell across the street to the person in a very friendly way, just to find out when the person turns toward you that he is a total stranger (making you feel quite foolish as a result). In this case, top-down processing took over inappropriately. Analogies can be one way to capitalize on top-down processing in instruction. When students are given instruction in an area or domain in which they are not familiar, analogies can provide a bridge between where the students are and where the instruction is going to take them, assuming that the students understand the analogy (Newby & Stepich, 1987). As described in chapter 2, graphics can be a very appropriate basis for presenting analogies to students.
Three processes are crucial to the encoding and retrieving processes (E. Gagné, 1985): elaboration, organization, and spread of activation. Elaboration is a process whereby supporting information is added to the information being learned. Elaboration occurs when an individual uses knowledge already stored in LTM to enhance, extend, or modify new information while in STM, as well as during subsequent transfer into LTM. In the propositional network model, elaborations provide links between previously stored propositions and new information. Effective elaborations serve to combine or link related propositions to stimulate retrieval of the learning context; ineffective elaborations do not (Reder, 1982; see also Wang, 1983). Several simple, but effective elaboration strategies have proven effective in improving retrieval, such as, again, the use of analogies (Hayes & Tierney, 1982). Linden and Wittrock (1981) reported that simply reminding learners to elaborate during learning helped to facilitate retrieval.
Whereas elaboration affects the storage of information, spread of activation increases linkages among related propositions and nodal links in the propositional network. It is a process whereby a given active proposition passes activation along to related propositions. Isolated information in LTM is not easily activated, since few paths to other propositions exist. Certain information is difficult for individuals to recall because retrieval is dependent on a limited number of very specific prompts or cues. In order for activation to spread, direct links must be established between the propositions. Several researchers have advocated the use of a type of visual networking of information in textual materials, also known as spatial mapping, as an instructional technique (see studies by Chi & Koeske, 1983; Holley & Dansereau, 1984; and Novak & Gowin, 1984).
In addition to elaboration and spread of activation, successful learning requires dividing and organizing information into subsets. People attempt to organize information automatically and spontaneously (Reitman & Reuter, 1980), though success and efficiency vary widely for retrieval purposes. Organization, the intentional shaping of information into meaningful parts, plays a key role in effective retrieval of learned materials (Frase, 1973; Meyer, 1975; Thorndyke, 1977). Effective organization may provide additional pathways among network nodes in a manner similar to elaboration. Organization might also help overcome some of the inherent memory limitations of STM. The organization of information into subsets might also help provide pointers in STM that help individuals manage large amounts of interrelated information in LTM (E. Gagné, 1985; Glynn & Di Vesta, 1977).
The Role of Prior Knowledge
Prior knowledge is paramount to all aspects of cognitive psychology (see, for example, Di Vesta, 1987; Mayer, 1979; Shuell, 1986; Tobias, 1987). Its significance is probably best summarized by David Ausubel (1968, epigraph): "If I had to reduce all of educational psychology to just one principle, I would say this: The most important single factor influencing learning is what the learner already knows. Ascertain this and teach him accordingly." Ausubel (1963) maintained that the availability, organization, and strength of existing supporting cognitive structures are the foremost factors governing the meaningfulness of newly learned material, as well as the ease and efficiency of acquisition and retention.
For cognitive psychologists, prior knowledge also provides the potential for supporting schema related to forthcoming instruction, improved capacity for comprehension monitoring (Garhart & Hannafin, 1986), and individual lesson choices (Gay, 1987), and the capacity for elaboration and meaningful learning. The availability of related prior knowledge permits the learner, to a degree, to uniquely define information needs. When supporting knowledge exists, learners gain the capacity to compare and contrast to-be-learned instruction within existing knowledge, providing uniquely relevant elaboration unavailable to learners with limited prior knowledge. Consequently, lesson knowledge generally will be encoded more meaningfully and retrieved more successfully by learners with high versus low prior knowledge.
VISUAL COGNITION
Visual cognition includes all the mental processes involved in the perception of and memory for visual information (Pinker, 1984). Perception is the process of selectively attending to and scanning a given stimulus, interpreting significant details or cues, and, finally, perceiving some general meaning (Levie, 1987). Memory for visual information involves the cognitive processes of storing and recalling information from visual stimuli. It is difficult to pinpoint where perception ends and cognition begins. For this reason, we will deal with the issues of perception and memory independently.
Visual Perception
Visual perception is the process of being able to selectively attend to and then subsequently perceive some meaning from a visual display. All the senses are involved in perception, although the visual sense is usually stressed in most perceptual theories. Most people usually think of visual perception in terms of human physiology, or the "mechanics of seeing," such as how the eye receives visual stimuli, and converts and transmits this information as an electrochemical signal along the optic nerve until it reaches the visual cortex of the brain, as that shown in Figure 4.3. However, visual perception is "more than meets the eye." Certainly, the physiology that accounts for perception is remarkable; however, it's not the issue here. Instead, we are concerned with what happens to the information once it reaches the processing centers of the brain. Visual perception is far from an objective process and instead is based on all our previous knowledge and experiences. The use of prior knowledge to guide perception is known as knowledge-guided perceptual analysis, better known as top-down processing. Visual perception is not like taking a photograph with a camera.
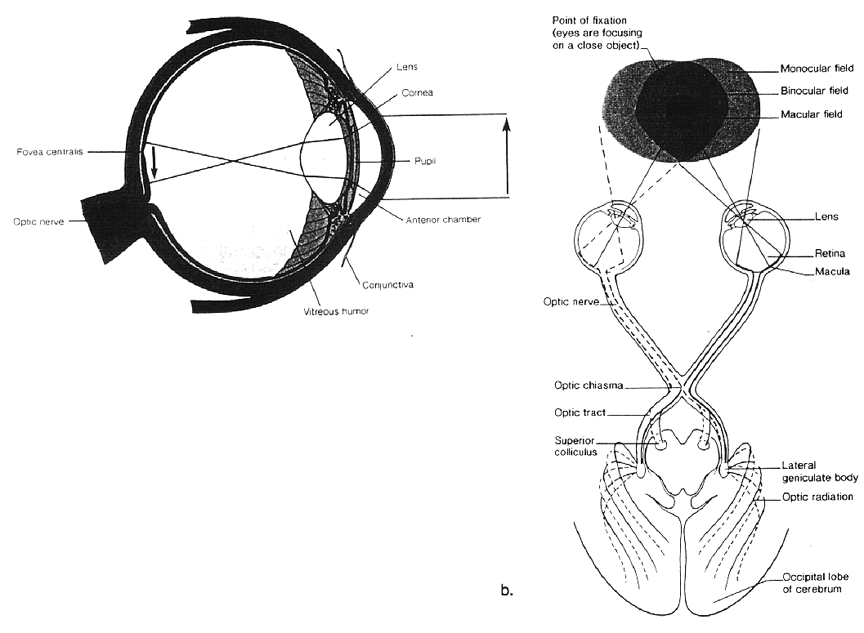
Figure 4.3
Some of the physiological mechanics of perception: the left eye and the visual centers of the brain (both views are from the top).
Visual perception is largely concerned with visually recognizing shapes and patterns of objects directly in our visual field. There are several traditional theories of pattern recognition, such as template matching and feature models. All of these traditional approaches assert that knowledge about the regularities of the world is used to limit the number of possible recognizable shapes from which the perceptual system can choose. Gestalt psychologists from the 1920s, such as Max Wertheimer, Kurt Koffka, and Wolfgang Köhler, were among the first to be interested in visual cognition. Whereas one might define perception on the basis of the individual elements (structuralism) in the visual display, Gestalt psychology defined a series of perceptual principles based on global characteristics. These principles are still useful in studying pattern recognition, where the total is more than the sum of the parts.
Four gestalt principles are still particularly relevant to designing instructional visuals. The first principle, closure, is based on the idea that humans naturally look for meaning. This principle accounts for the phenomenon of seeing dead presidents in fluffy white clouds.
Study Figure 4.4 for a moment and try to find a recognizable object. At first, all you might see is a random scattering of ink blotches. Here's a hint if you are having trouble seeing something further: look for an animal. Still having trouble? Look for a dog. Once people see the figure, they instantly recognize not only a dog, but a Dalmatian. Once you achieve recognition of this figure, begin to reflect on the elaborated meaning you begin to attach to it, such as a dog eating something, or retrieving a thrown stick.

Figure 4.4
An example of the principle of closure. Do you see a smattering of ink blotches, or something more meaningful? Read the preceding page for some clues.
Similarly, look at Figure 4.5. Again, what do you see? Most people instantly see a young girl of about 20 with her head turned away. Look again and you might see something completely different. Instead of a young girl, there is an old woman. The young woman's left cheek becomes the old woman's big nose. The interesting point from a perceptual point of view is that it is impossible to see both at the same time. Your perceptual system will not allow it. Even though you may switch rapidly between the two meanings, you cannot accept both simultaneously. Again, reflect on the meanings you might be tempted to attach to either meaning. Perhaps thoughts quickly went through your mind of the young girl going hurriedly off to meet her fiancé, or the old woman waiting in line for groceries. Your mind wants to attach meaning to visual displays.

Figure 4.5
Another example of the principle of closure. There are two distinct meaningful images here. Can you see both of them?
The other three gestalt rules for the organization of visual information are the principles of proximity, similarity, and continuity. The principle of proximity states that objects physically closer to one another will be perceived as being grouped together in some meaningful way. Look at the dots in Figure 4.6. One quickly judges that there are five columns of five dots each, simply because of the spatial distances. The principle of similarity simply states that similar objects also will be grouped together in a meaningful way. Look at the way the circles appear to be "surrounding" the one "lonely" cross in Figure 4.7. Figure 4.8 illustrates the principle of continuity: The line is perceived as unbroken and continuous because the mind looks for unity in objects.
People perceive meaning from animated visuals when they are tricked into seeing something that really is not there. Certain perceptual factors help to explain this phenomenon (Rieber & Kini, 1991).

Figure 4.6
An example of the principle of proximity. The physical closeness of some of the dots make natural groupings of five columns.
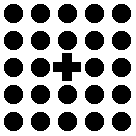
Figure 4.7
An example of the principle of similarity. The cross appears to be "surrounded."

Figure 4.8
An example of the principle of continuity. The two line segments are perceived as one continuous line.
Perceptual Factors Related to Animation
Motion perception research has a long history. Animation is an example of apparent motion, or the phenomenon of seeing motion when there is actually no physical movement of an object in the visual field (Ramachandran & Anstis, 1986). In contrast, a person perceives real motion when a moving object actually triggers visual detecting neurons (Schouten, 1967). Apparent motion results when two or more static objects, separated by a carefully determined distance, are alternately presented to the observer over time. Even though there is no actual motion of the image on the eye's retina, the visual system perceives motion by combining this discretely presented information into a smooth and continuous set. When the conditions are just right, the mind fills in the gaps between the frames, resulting in the perception of continuous motion, even though it is only being confronted with a rapid series of still images. You see examples of apparent motion everyday, such as when moving arrows created by carefully timed neon lights try to attract your attention to a particular store.
The most intensively studied version of apparent motion is known as stroboscopic motion, or the motion perceived when two lights are presented at different times and different locations (also called beta movement) (Kaufman, 1974; Schiffman, 1976). Stroboscopic motion has a critical threshold of about 16 frames per second in order for it to be perceived as smooth and continuous; anything less results in choppy or jumpy displays. Even the most inexpensive computer systems available today easily match this critical rate.
The phi phenomenon is closely related to stroboscopic motion (Schiffman, 1976). This illusion of motion is produced when stationary lights are turned on and off in sequence. Examples include the use of carefully sequenced lights to create dynamic visuals around billboards, theater marquees, scoreboards in sports arenas, and other "Las Vegas-like" displays. The phi phenomenon also accounts for any animation on computer displays produced by the coordinated switching of pixels. Several perceptual theories help to explain both stroboscopic motion and the phi phenomenon. (It is interesting to note that other examples of apparent motion have been identified, such as the delta phenomenon, produced when the brightness of the stimuli is varied [William, 1981].)
There are many factors that determine the nature of apparent motion. However, three are particularly relevant to computer animation: (1) the time between projection of the separate displays; (2) the light intensity of the displays; and (3) the spatial distance between each of the displays. For example, no motion will be perceived when two lights are alternately presented at too slow a rate. Instead, one simply sees two lights being switched on and off. If the lights are alternated at too fast a rate, then the two points are perceived simultaneously and, again, no motion will be perceived. However, if the two lights are alternated at just the right speed, the perception that a single object is moving back and forth will be induced. The light intensity of the two points and the space between them must also be just right.
Although each of the three factors described above must be considered individually, "Korte's law" states that apparent motion can only result when these three factors are properly synchronized (Korte, 1915, as cited in Kaufman, 1974; and Carterette & Friedman, 1975). If one factor is held constant, then the other two factors will vary proportionally (though not necessarily directly). For example, if light intensity is held constant, the distance between the displays must vary proportionally to the amount of time between each display for apparent motion to be produced. So, as the displays are moved closer together, the time between the projection of the displays must also decrease. Many other factors, such as spatial orientation, depth, color, size, shape, and texture, also impact the perception of apparent motion, but the influence of each of these factors is considered minimal.
In order for a group of intermittently displayed objects to be perceived as one object in continuous motion, the visual system must trigger a psychological process called correspondence (Mack, Klein, Hill, & Palumbo, 1989; Ramachandran & Anstis, 1986; Ullman, 1979). In this process, the brain imposes one organized and meaningful pattern to the separate images. For example, an animated scene of a person riding a bicycle across the computer screen may actually consist of 30 separate frames. Although the visual system "sees" all 30 frames, an individual perceives only one object in motion. The correspondence process cognitively "assembles" the separate images into one meaningful set; motion becomes the "glue" in this assembly. Explaining how the visual system achieves correspondence detection is controversial in visual cognition research. Perceptual psychologists have shifted from the view that apparent motion is the result of a single psychological process over the years to a two-process theory where two distinctly qualitative processes are at work: long-range and short-range apparent motion (Braddick, 1974, as cited in Petersik, 1989; Julesz, 1971). Motion is perceived using either or both of these processes. (Research indicates that there is competition between the two processes when each is equally stimulated. Researchers have not yet adequately determined the conditions necessary to trigger one or both processes [Pantle & Picciano, 1976].)
The short-range process of perceiving motion relies on the brain solving a complex mathematical matching game. First, a display stimulates the retina and the image is transformed into an array of tiny points of varying brightness. Second, this image is converted into an electrical signal and is carried along the optic nerve to the brain. Third, the brain compares each point with corresponding points in each successive display and determines that one set of matched points composing a single object has changed its position. The way the brain achieves this complex mental computation is not yet understood (Petersik, 1989).
The long-range process of perceiving motion provides a very different explanation. It holds that the visual system uses strategies that limit the number of matches the brain needs to consider in order to avoid the need for a complex point-to-point comparison (Ramachandran & Anstis, 1986). Instead, it is believed that the visual system uses a number of special strategies evolved over thousands of years. Given the regularities of the physical world, the visual system extracts the most relevant features from a complex display (such as clusters of dots rather than individual dots) and then searches for those features in the successive images. The features could be edges, short outlines, blotches of brightness and darkness, or texture. The visual system limits motion perception to events consistent with universal physical laws. Long-range motion perception is based on the assumption (usually at a subconscious level) that the physical world is organized and predictable, not chaotic and random. Such assumptions lead the visual system to perceive one kind of motion in "preference" to other kinds. For example, linear motion is perceived over abrupt changes. The visual system also anticipates the need for objects to overlap at times; therefore, the unseen objects still will be perceived to exist (Ramachandran & Anstis, 1986). This is similar to the principle of continuity described earlier.
In summary, apparent motion explains how the illusion of motion is produced from a wide assortment of media, such as motion pictures (including film, videotape, laser disc, and television), theater marquees, scoreboards, billboards, and animation produced by computer. Smooth and continuous motion perception is largely dependent upon the rate of picture presentation. The next time you watch a movie, try to remember that your attention to the plot, script, and acting would not be possible without the projector or player first displaying the individual photographic frames at the proper rate, followed by your visual system fusing each successive frame into one continuous and integrated set.
Memory Considerations for Visual Information
Active visualization in short-term memory is an accepted, though not universal, phenomenon. Strong evidence comes from classic studies where subjects were asked to mentally rotate letters and other three-dimensional objects (Pinker, 1984), such as the example described in Figure 4.9. This research has shown convincingly that the time it takes people to determine whether a given rotated letter is normal or mirror-reversed increases depending on how far it deviates from an upright position (e.g., Cooper & Shepard, 1973). Similarly, determining whether 2 three-dimensional objects have the same shape has been shown to be a linear function of how different their orientations are represented. A simple example is how people determine moderate to complex compass directions, such as in the activity in Box 4.1. Consider how you use visualization techniques to construct meaning for phrases such as "Northeast."
In contrast to visualization in STM, the question of if and how visually based information is stored in and retrieved from long-term memory is more controversial. Retrieving information from long-term memory to produce internal visual images in short-term memory can be described as "the process of remembering or reasoning about shapes or objects that are not currently before us but must be retrieved from memory or constructed from a description" (Pinker, 1984, p. 3). There is considerable evidence that, in general, memory is greater for pictures than for words. People are particularly adept at remembering certain kinds of visual information. Many studies show that people's recognition memory for pictures is extraordinary. For example, Shepard (1967) showed 612 different pictures to people. When tested immediately afterward, subjects correctly recalled more than 98% of the pictures. Even a week later, subjects recalled more than 85% of the pictures. These kinds of results were repeatedly found in similar tests of recognition for visual information, such as photographs and faces (e.g., Nickerson, 1965; Standing, Conezio, & Haber, 1970).
Two competing theories about this "picture superiority" effect have been offered. The first, called dual coding theory, proposes that long-term memory consists of two distinct, though interdependent codes, one verbally based and the other visually based (Paivio, 1990, 1991; Clark & Paivio, 1991). The second theory suggests that all information is represented by a single propositional coding model. Since neither theory is physiological in nature, the arguments for and against each theory are useful only in finding a reasonable model that helps us to better understand thought processes and make better instructional decisions. Useful perspectives can be gained from considering both dual coding and propositional theories. Of the two theories, however, dual coding has considerable empirical support (Anderson, 1978) and is the theory favored here. The next two sections describe dual coding theory and contrast it to the alternate propositional hypothesis.

Figure 4.9
Here is an example of the mental rotation research that provides strong evidence for visualization in short-term memory. The activity simply asks subjects to respond "true" if the letter shown is in its normal position, although rotated, or "false" if the letter is shown as "mirror-reversed." The letters that are rotated more from the original position consistently take people longer to respond, suggesting that people must mentally rotate the figure back to the upright position before being able to respond with 100% confidence.
|
|
|
Here's a little map activity which requires you to actively visualize in short-term memory. Below is a map of Texas with letters of the alphabet scattered about. See how long it takes you to answer each of the following questions under the condition that you must be correct each time. As you answer the questions, take note of the visualization techniques you use to get the right answer. Also consider which questions took you the longest and shortest time to answer and why. 1. Which letter is southwest of Austin? 2. Which letter is furthest south in the state? 3. Which letter is northeast of Dallas? 4. Which letter is southeast of San Antonio? 5. Which letter is in the northeast corner of the state? 6. Which letter is in the southeast corner of the panhandle? 7. Which letter is furthest west and in the state? 8. Which letter is east of Houston? 9. Which letter is west of Dallas? 10. Which letter is directly north of San Antonio? 11. Which letter is northeast of Brownsville?
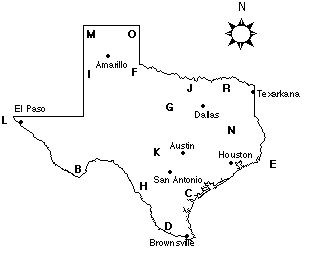 |
An Overview of Dual Coding Theory
Dual coding theory is a complete set of assumptions and hypotheses about how information is stored in memory (Sadoski, Paivio, & Goetz, 1991). Dual coding theory suggests that memory consists of two separate and distinct mental representations, or codes -- one verbal and one nonverbal. The verbal system is "language-like" in that it specializes in linguistic activities associated with words, sentences, and so on. Although the nonverbal system includes memory for all nonverbal phenomenon, including such things as emotional reactions, this system is most easily thought of as a code for images and other "picture-like" representations (although it would be inaccurate to think of this as pictures stored in the head). For simplicity and clarity, we will refer to the nonverbal elements of dual coding as the visual system.
Dual coding supports the idea that knowledge is represented on a concreteness-abstractness continuum and that human cognition is predisposed to storing mental representations in one of two forms corresponding to the ends of the continuum. At one end are the visually based representations in which knowledge is stored in concrete and nonarbitrary ways. For example, the image of an airplane necessarily resembles characteristics of the real thing. At the other end are the verbal, or semantic, representations in which knowledge is stored in discrete and arbitrary ways. There is no natural reason that the word "airplane" must be used to represent the real object, for example. The most fundamental memory units are called logogens in the verbal system and imagens in the visual system.
Both the verbal and visual subsystems have unique properties. Logogens are stored in the verbal system as discrete elements, resembling words and sentences, whereas imagens are stored as continuous units in the visual system having an "all-in-oneness" quality. This is similar to the difference between digital and analog information. Although the two coding systems are assumed to be structurally and functionally separate, they can become interconnected. Informational units in one system can cue or trigger elements stored in the other.
As shown in Figure 4.10, dual coding predicts that three distinct levels of processing can occur within and between the verbal and visual systems: representational, referential, and associative. Representational processing describes the connections between incoming stimuli and either the verbal or visual system. Verbal stimuli directly activate verbal memory codes, whereas visual stimuli activate visual memory codes. For example, hearing the word "dog" first activates the verbal system, but seeing a picture of a dog directly activates the visual system.
Referential processing is the building of connections between the verbal and visual systems. Hearing or reading the word "dog" will stimulate the appropriate logogen in the verbal system. Subsequently forming a mental image of a dog, perhaps your own pet, implies that the verbal system has directly activated the imagen corresponding to your pet. The other direction is also possible, such as a person who is asked to name a given picture of a dog and says "collie." An important assumption of referential processing is that these connections between the verbal and visual system are not necessarily one to one, but can be one to many. Hence, showing a picture of a dog may invoke many different verbal responses, such as "animal," "dog," "collie," or "Rover."
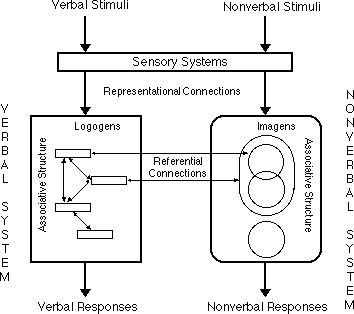
Figure 4.10
A dual coding model for memory and cognition.
However, the example of a single picture evoking many different verbal labels can be explained two ways. First, the different responses may be the result of multiple links between the single imagen of the visual system and the many logogens of each verbal representation. Second, it is possible that the image was linked only to the logogen corresponding to "my pet Rover," which, in turn, invoked a search strategy within the verbal system resulting in something like "Rover is a collie, which is also a dog, which is also an animal."
Associative processing refers to the activation of informational units within either of the systems. However, processing in the verbal system is believed to be sequential or linear, whereas processing in the visual system is thought to be parallel or synchronous. Both imply hierarchical organizations, but access from one logogen to another versus one imagen to another is qualitatively different. If you form a mental image of the refrigerator in your kitchen for example, you can then decide to "look" left or right, up or down in your mind. Mental scanning can be accessed easily or quickly, regardless of which direction you choose to take. However, recalling the middle line from the "Pledge of Allegiance" requires a linear or sequential search from beginning to end implying a very different storage mechanism for verbal information.
Dual coding theory predicts that pictures and words provided to students will activate each of these coding systems differently. The superiority of pictures for memory tasks is explained by dual coding on the basis of two important assumptions (Kobayashi, 1986). The first is that the two codes produce additive effects. This means that if some piece of information is coded both visually and verbally, the probability of retrieval is doubled. The second assumption is that the ways in which pictures and words activate the two codes are different. Pictures are believed to far more likely to be stored both visually and verbally. Words, on the other hand, are less likely to be stored visually. For example, if a picture of a bus is shown to someone, dual coding theory says the picture provides adequate cueing to the visual memory trace and the individual is very likely to also add semantic labels. Thus, the picture is being stored in long-term memory two times, once visually and once verbally. On the other hand, if just the word "bus" is shown to someone, the verbal code may be activated, but the visual code may not be activated unless the person actively forms and processes an internal image of the bus. Information that is dually coded is twice as likely to be retrieved when needed because if one memory trace is lost (either verbal or visual) the other is still available. When it comes to memory, two codes are better than one.
Instructional designers should be most interested in ways to increase the likelihood that information will be dual encoded in long-term memory. Information encoded in both verbal and visual forms with strong and flexible links between the codes should enhance retention, retrieval, and transfer. Dual coding is more likely to occur when the content lends itself to imaging (Paivio & Csapo, 1973). Concrete concepts, like "tree" or "house," are good examples of information that readily produce internal images in most people. Concrete concepts are easier for people to visualize simply because they refer to tangible objects that have a physical form. Conversely, people do not automatically form internal images for abstract concepts, like "patriotism" or "kindness." In these cases, it is often useful to provide the learner with a prototype image that communicates the most important characteristics or attributes of the concept (Klausmeier, 1990), such as two people shaking hands to represent "friendship." This prototypical image is frequently analogical to the concept (Newby & Stepich, 1987), like the example discussed in chapter 2 of a blindfolded woman holding a set of scales to represent justice. Research shows that words, sentences, and paragraphs that are easy for people to form internal mental images of are generally recalled better than those that are difficult to imagine. Dual coding theory provides a plausible explanation for this empirical evidence. It is also useful to note that it is generally believed that the primary code for concrete concepts is visual, that the primary code for abstract concepts is verbal, and that concrete concepts are learned before abstract concepts.
Arguments Against Dual Coding Theory
In contrast to dual coding theory, propositional theories suggest that all information can adequately be stored in long-term memory in semantic or verbal form, similar to the idea of a propositional network described earlier. Therefore, the assertion that a second code is not needed discounts dual coding on the principle of parsimony -- the idea that all things being equal, a simpler model should be preferred to one that is more complex.
Propositional theories suggest a process where visual information is transformed into a semantic form. Incoming visually based information from the environment is converted into propositions as the information is passed from short-term to long-term memory. When retrieved, the propositions are transformed back into visual information, as shown in Figure 4.11. This is analogous to how a computer stores information about a graphic in memory on a disk. Information about a graphic appearing on the computer screen (i.e., STM) is converted to digital form for storage on a disk (i.e., LTM). This digital information must later be retrieved from disk, processed, and redrawn on the computer screen for the information to reappear as a picture.
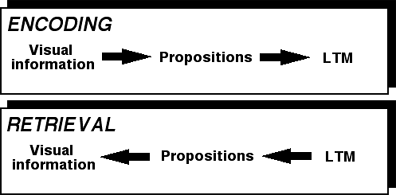
Figure 4.11
Proponents of a propositional or semantic model of encoding of visual information in long-term memory suggest that visuals are converted to propositional form as they are encoded, or "passed," from short-term to long-term memory and reconstructed again into visual form when later retrieved back into short-term memory.
Introspection data of people reporting seeing "pictures in their heads" suggests that they are processing the information in short-term memory. Most propositional theorists do not argue against imagery in short-term memory; their arguments are only related to the way information is stored in long-term memory. Propositionists explain empirical evidence of the superiority of pictures over words on the basis of increased elaboration. That is, people provided with pictures just naturally spend more time and effort processing pictures. People process and rehearse pictures more fully than words and sentences. This rehearsal results in more propositional information, as well as more durable traces between the propositions stored in long-term memory, when visual representations are provided than when information is given only in verbal form.
Proponents of a pure propositional theory contend that simple everyday examples show the inadequacy of a dual coding approach. For example, people are usually unable to remember simple facts about objects that they come in contact with every day. Does Lincoln face left or right on a penny? If stored visually, it should be a matter of simply recalling the image from long-term memory and looking for this one detail. Propositionists would say that the image of a penny is not actually stored in memory, only bits of information that, when reconstructed, form the image. Since the proposition related to the "direction of Lincoln's profile" is not a salient feature for most people, it is usually a toss-up between left or right. As another example, visualize the Washington Monument. Now, how many windows are there at the top on any one side? If stored visually, it should just be a matter of counting. Of the many bits of information stored for "penny" and "Washington Monument," there is no reason why either of these should be rehearsed; therefore, they are not stored. Upon reconstruction, the informational "holes" become obvious only when pinpointed.
Proponents of dual coding meet this challenge by suggesting that a proposition-only theory soon collapses under its own weight. The amount of information contained in even simple images, such as the square shown in Figure 4.12, and the subsequent mental processing necessary to adequately relate the information make pure propositional models impractical. Contrary to a pure propositional model, proponents of the dual coding model suggest that long-term memory is predisposed to verbal and visual information. Dual coding advocates suggest that proposition-only models soon collapse under their own weight. For example, the amount of pure propositional information contained in even the simplest visuals, such as this square, is staggering. What, then, would be all of the individual propositions necessary to define even one face? Although the debate over which model more adequately represents actual human cognition may never be resolved, dual coding appears to provide instructional designers with a useful theoretical framework for designing and developing instructional visuals.
Memory for Animated Visuals
Animation, like any picture, should aid recall when it illustrates highly visual facts, concepts, or principles. However, the difference between animated graphics and static graphics for memory tasks is not as clear. Animated graphics are probably better at communicating ideas involving changes over time because of their ability to show motion. Animation should help reduce the level of abstraction for many temporal concepts and principles. For example, the motion of an animated car traveling from New York to Washington, accompanied by a display of the miles traveled and gallons of gasoline consumed, should help reduce the abstraction level for how to compute the average "miles per gallon." Learners would have to consciously work to connect the visual "snapshots" represented by static visuals for such problems. A common strategy is the use of abstract symbols, such as arrows and dotted lines, in the hope that these represent or suggest the motion attribute to learners. In contrast, animation triggers the automatic ability of the visual system to induce apparent motion, thus freeing short-term memory for other tasks.
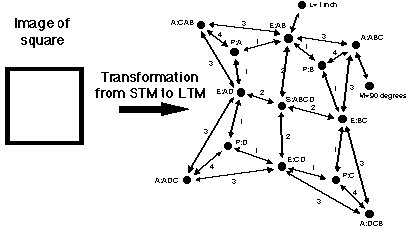
Figure 4.12
Contrary to a pure propositional model, proponents of the dual-coding model suggests that long-term memory is predisposed to verbal and visual information. Dual-coding advocates suggest that proposition-only models soon collapse under their own weight. For example, the amount of pure propositional information contained in even the simplest visuals, such as this square, is staggering. What, then, would be all of the individual propositions necessary to define even one face? This propositional network for a square was adapted from Larkin, McDermott, Simon, & Simon (1980), where "nodes represent corners (P), edges (E), angles (A), and the surfaces (S). Links connect corners with edges (1), edges with the surface (2), angles with edges (3), and angles with corners (4). Descriptors can be linked to nodes, as shown for the length (L) of Edge AB, and the magnitude (M) of Angle ABC" (p. 1337).
Many important concepts and principles not only change over time, but also change in a certain direction. The direction in which an object is moving is defined as its trajectory (Klein, 1987). For example, many concepts and principles in physical science demand that learners understand not only that an object is moving at a certain speed, but also that it is moving in a certain direction. An example is velocity, which is defined as the speed and direction of a moving object. The motion and trajectory of an object can be represented by both verbal and visual means. Film, video, or computer animation can provide visual representations and verbal representations can be conveyed by words such as up, down, fast, or slow. Dual coding theory suggests that the learning of facts, concepts, or principles involving motion and/or trajectory should be facilitated by instruction that presents appropriate combinations of visual and verbal representations of these attributes due to increased likelihood of redundant encoding.
Static visuals would be sufficient for tasks that only require learners to visualize information. However, if a task demands that learners understand changes over time or in a certain direction, then static visuals can only hope to prompt learners to mentally construct these attributes on their own. (See Footnote 1) However, animation makes this cognitive task more concrete and spontaneous by providing the motion and trajectory attributes directly to the learner. This would reduce the processing demands on short-term memory and should increase the potential for successful and accurate encoding into long-term memory. Just as dual coding theory would predict, preliminary research has shown that animation displayed with accompanying narration produces greater retention and recall than when either are presented separately or when verbal descriptions are presented before or after the animation (Mayer & Anderson, 1991).
MOTIVATION
Up to this point, the theoretical nature of this chapter may be setting a rather dull tone to human learning. In reality, human learning is an amazingly complex and dynamic interchange of events that current theory sorely falls short of capturing. The cognitive orientations discussed so far hopefully speak to the role of the individual in determining whether learning will occur. The most well-articulated, well-organized, and well-managed instruction will not have a chance to be effective unless it takes into account all the social and motivational factors within which instruction takes place (Weiner, 1990). What motivates an individual to initiate and complete a task? Interpretations have been offered from many points of view. We will again look at this issue from behavioral and cognitive perspectives.
Given the behaviorist's general lack of interest in nonobservable aspects of learning, it may surprise many that motivation plays an important role in traditional behavioral models. Although motivation can be conceptualized in a number of ways, perhaps the most common view of motivation for behaviorists is related to the strength of the reinforcement stimuli -- the stronger the reinforcement, the stronger the motivation to respond. As motivation increases, heightened levels of arousal become evident. Learners are thought to seek positive reinforcement through producing desired responses during instruction. If the presumed positive reinforcers are viewed as marginal, neutral, or negative by learners, then the motivation to seek the reinforcement by producing a response decreases. Traditional school and training situations abound with the use of extrinsic motivators, such as stars, report cards, or paychecks. As previously mentioned, graphics are frequently used as extrinsic motivators, such as when a graphic, like Superman, appears as a reward to a correct response. However, care must be taken not to "turn play into work," as research suggests that the well-intentioned use of extrinsic motivators, such as grades, can destroy the natural appeal of an activity for some children (Condry, 1977; Greene & Lepper, 1974; Lepper, Greene, & Nisbett, 1973).
Although cognitive psychologists do not discount the role and reality of extrinsic motivation, most look at motivation from a different perspective. For example, we all experience times when we choose to complete an activity not because of the promise of some external reward, but because the activity itself is satisfying and enjoyable. Intrinsic motivation refers to times when a certain activity is its own reward. When activities are intrinsically motivating, people demonstrate continuing motivation by choosing to participate even after external pressures to do so are removed (Deci, 1975, 1985; Kinzie & Sullivan, 1989; Maehr, 1976).
As the motivation literature suggests, the design of activities in which learners demonstrate commitment and perseverance in the thoughtful completion of a task depends on the degree to which the activity is perceived as relevant and its completion as personally satisfying (Keller & Suzuki, 1988; Lepper, 1985). By definition, a meaningful learning context is an intensely personal affair. The goal in education, however, is to discover contexts that have a wide appeal to learners of varying interests and aptitudes. LOGO (see chapters 3 and 8), for example, seems to attract the attention of children through the use of interactive computer graphics to produce interesting visual designs.
Ordinary people differ in their explanations of why they succeed or fail at a task. Attribution theory suggests that people interpret their ability to succeed as caused or controlled by several attributes. For example, some people see themselves as in control of their success, whereas others do not and instead believe that external forces control their destiny (Rotter, 1954; Weiner, 1979). One's perception of control over one's success can lead to different patterns of time, effort, and attention to a given task. Another potent attribute is one's perception of how stable the cause of success is over time, whether it is temporary or permanent. Stability is evidenced by questions such as "I was successful today, but will I be able to do it tomorrow?" Obviously, instruction should lead people to believe that they control the frequency and stability of their own success (Milheim & Martin, 1991).
Probably the most applied instructional motivation model is the ARCS model by John Keller (1983, 1988), named after its four components: Attention, Relevancy, Confidence, and Satisfaction. As previously discussed, getting and sustaining a student's attention is a prerequisite cognitive task for any and all subsequent learning. Tasks must be individually relevant to one's needs and expectations. For some people, relevancy may be future-oriented, such as perceiving that a skill will help them in some way in the future; for example, getting a good job or a promotion. For others, relevancy is more present-oriented, meaning that a task will be considered relevant if it satisfies an immediate need, such as providing social rewards with friends or pertinent information to an important question. People generally need to feel confident that they are likely to succeed at the task at hand. It is not that the task need be or should be easy, but success should be within their grasp. People generally have a need to maintain a positive self-image. Feelings of impending success can trigger such an attitude. Lastly, people will generally seek to maintain participation in activities they perceive as interesting and relevant. In other words, we find such activities satisfying. One of the main characteristics of satisfying experiences is that people generally will continue to participate once external pressure to do so has ceased.
Similar to the ARCS model, Malone (1981) has suggested a framework of intrinsically motivating instruction based on challenge, curiosity, and fantasy. Tasks need to be designed to be optimally challenging -- not too easy or too difficult. But perhaps most important, the tasks should elicit feelings of competence, or self-efficacy, as students solve problems they perceive as relevant and important. This enhances one's self-concept and leads to a feeling of control over one's own success (Weiner, 1979, 1985). Similarly, a person's curiosity is usually piqued when an activity is viewed as novel or moderately complex. Curiosity is also usually increased by activities that offer an element of surprise. This occurs when the expected and actual outcomes of an activity are different or incongruent, a phenomenon that Berlyne (1965) termed "conceptual conflict." Again, however, both challenge and curiosity produced by a conceptual conflict must be optimally maintained to be effective. A task perceived by students as too easy quickly loses appeal, and a task perceived as too demanding is avoided. Likewise, a conceptual conflict between expected and actual task outcomes can make a learner seek to resolve the conflict, but can quickly lead to frustration if the conflict is too confusing or bewildering. Norman (1978) has termed optimal levels of conceptual conflict as "critical confusion." Fantasy entails providing students with a meaningful context for learning that easily triggers their imaginations. In addition, young students easily transfer such fantasy contexts to play activities. Chapter 8 applies this model of motivation to the design of simulations, games, and microworlds.
Graphics offer the potential to increase the challenge and curiosity of a task, as well as encouraging students to be creative and use their imaginations. Recall from chapter 2 that motivation was one of the instructional applications of graphics. This can be interpreted and applied as including both extrinsic and intrinsic motivation. However, the other instructional applications of graphics also can be understood in relation to motivation as well. Cosmetic and attention-gaining applications are more closely related to extrinsic motivation, akin to the phenomena of "wanting" to go through the instruction because of all the "pretty pictures." On the other hand, graphics for presentation and practice are more closely related to intrinsic motivation by helping to create an intrinsically interesting learning environment. Certainly, the use of graphics as visual feedback during practice activities, including simulations, can provide an intensely satisfying and challenging learning environment. For example, graphics can easily trigger the illusion of going on a "safari" to find "c" words or getting students to use their estimation skills to "save a whale."
Finally, intrinsic motivation is just one of the characteristics of self-regulated learning, defined as "individuals assuming personal responsibility and control for their own acquisition of knowledge and skill" (Zimmerman, 1990, p. 3). In addition, self-regulated students are metacognitively and behaviorally active (Zimmerman, 1990). Metacognitive attributes involve the student's attempt at the planning, goal-setting, and organization of learning in tandem with self-monitoring and self-evaluation (Borkowski, Carr, Rellinger, & Pressley, 1990). These attributes subsequently lead students to take appropriate actions associated with their own learning, such as the selection, structuring, and creation of environments that will best suit their learning styles and needs.
The advantages of self-regulated learning are obvious. Students become not only more active in the learning process, but also assume responsibility for it. The implication is that students do not simply participate in a given lesson, but actually help design it. At issue is what instructional designers should consider in helping to nurture the self-regulation process. Certainly, learning environments should be designed with a "self-oriented feedback loop" to provide a rich and continual stream of feedback to students to help them establish and maintain goal-setting and goal-monitoring (Zimmerman, 1989). Schunk (1990) referred to students' deliberate attempts to attend to and evaluate their behavior in relation to their goals as self- observation and self-judgment.
REVIEW